HP Tech&Device TV 内のコンテンツを検索します。
2019.08.16
フェイクデータが本物以上の価値を持つように。データで生まれる新たな可能性。







データの重要性が叫ばれる中、企業内に「使えないデータ」が蓄積されていることにも注目が集まっている。
「使えないデータ」の大半が利用価値が見出されていないダークデータだと言われているが、データ自体の有用性がわかっていても、さまざまな事情により利用が制限されているデータも存在している。
個人情報に関連するデータが最たる例だ。
GDPR(EU一般データ保護規則)や米カリフォルニア州の消費者プライバシー法などが施行され、企業による個人情報に関するデータの利用が困難になっている。工場の稼働率や実験結果などのデータと違い、個人情報関連のデータは流出した際のリスクが極端に大きくなってしまっているのが現状だ。
この現状に一石を投じるため、ディープラーニングを使用し、データの価値をほとんど失わないシンセティックデータ(フェイクデータ)を作り上げるシステムを提供しているMostly AIという企業がある。
アルゴリズムにより人工的に作られたデータ。テストデータセットとして機械学習モデルへの応用が進んでいる。
Mostly AIは2019年4月23日に経済産業省の後援を受け、日本経済新聞社が主催したグローバルイベント「AI/SUM」で目玉プログラムの一つだったピッチコンテスト「World 30」において、世界中の参加企業の中からSony Awardを受賞したオーストリアのスタートアップだ。
本記事では、シンセティックデータの専門集団であるMostly AIのアレクサンドラ・エバート氏が語るデータ活用の未来の姿をまとめた。
規制により注目が増すシンセティックデータ
2010年代、ディープラーニングというブレークスルーとともにAIへの注目度が一気に増した。
さまざまな業界の業務に組み込まれるようになり、世界経済に大きな価値をもたらし始めたAIだが、同時にデータ保護という大きな懸念も世界にもたらした。
近年、GDPRや米カリフォルニア州の消費者プライバシー法などが施行され、各国が個人情報保護に向けて動き出している中、個人情報を含むデータを活用するには、データを加工し匿名化する必要がある。

──アレクサンドラ
「従来の匿名化データは、オリジナルデータの持つ構造や時間データ、他データとの相関性を破壊し、ほとんど意味のないデータに変換してしまいます。例えば、クレジットカードの利用履歴を匿名化する場合、取引内容の多くが暗号化され、意味のないデータに置き換えられます」

上来の匿名化に使われる方法ではオリジナルデータの持つ価値を保つのは困難だ。そこでMostly AIが開発した人工知能により作り出される高性能のシンセティックデータにより匿名化しつつ価値を保つことが可能になった。
アレクサンドラ氏は、従来の匿名化データの抱える問題は、限られた情報からユーザーを再特定できてしまう現状からきているという。
──アレクサンドラ
「銀行が保有する取引データは、わずかな原型が残っているだけで再特定のリスクが極めて高くなります。また、スマートフォンのような携帯端末においては、2箇所以上の移動データが残っていれば、約半数のユーザーを特定することが可能です」
AIによるAIのための教師データ作成

Mostly AIはディープラーニングを活用することで、ユーザーを再特定できないようデータに改変を加えつつ、オリジナルデータの持つ時間データやデータ同士の相関性をほとんど損なわずにシンセティックデータを生成できるという。
アレクサンドラ氏は、高度なシンセティックデータを低コストで生成可能になったことは、データ中心の現代に大きなインパクトをもたらすという。
アレクサンドラ氏の語るインパクトは以下の通り。
- プライバシー侵害リスクの低減
- オープンイノベーションの促進
- データの収益化
プライバシー侵害リスクの低減
アレクサンドラ氏は、データベースに保管されているオリジナルデータをシンセティックデータに置き換えることで、プライバシー侵害のリスクを大きく低減できるという。
──アレクサンドラ
「オリジナルデータの持つ価値をコピーしたシンセティックデータがあれば、オリジナルデータを保管する必要はありません。現時点で用途が見えていない個人情報を含むデータを抱えているということは、目に見えない爆弾を抱えているのと同じです。リスクはあっても見返りはないようなものですから」
ある調査では、社内に蓄積されたデータの85%は不要なデータとの結論に至っている。
たしかに、オリジナルデータの持つ価値を残したまま、リスクを取り払うことができれば「ホンモノを上回るニセモノ」が生まれることになる。
オープンイノベーションの加速
アレクサンドラ氏は、オリジナルデータをシンセティックデータに置き換えることで、データ活用は一気に加速すると語る。
──アレクサンドラ
「膨大なデータを蓄積している企業や公的機関などは多いですが、うまく活用できている組織はいまだに少ないままです。組織内では有用性を見出せていないデータでも、他者にとっては宝の山かもしれません」

従来、個人情報を含むデータを使ったハッカソンやコンペティションは開催が困難だったが、シンセティックデータ化し、リスクを排除したデータであれば、公開リスクは極めて低いといえる。
また、日本では公的機関が中心となってオープンデータ化を進めているが、個人情報を含むデータの取り扱いに関してはデータ活用先進国に大きく遅れを取っている現状だ。
現状からの脱却に、シンセティックデータが役立つことは間違いない。
データの収益化
そのうえ、シンセティックデータにはデータ流通市場の創出という可能性がある。
従来、データは組織内で利用するものだったが、近年のオープンデータ化の流れと相まってシンセティックデータは新たなデータ流通市場を生み出す可能性があるとアレクサンドラ氏は語る。
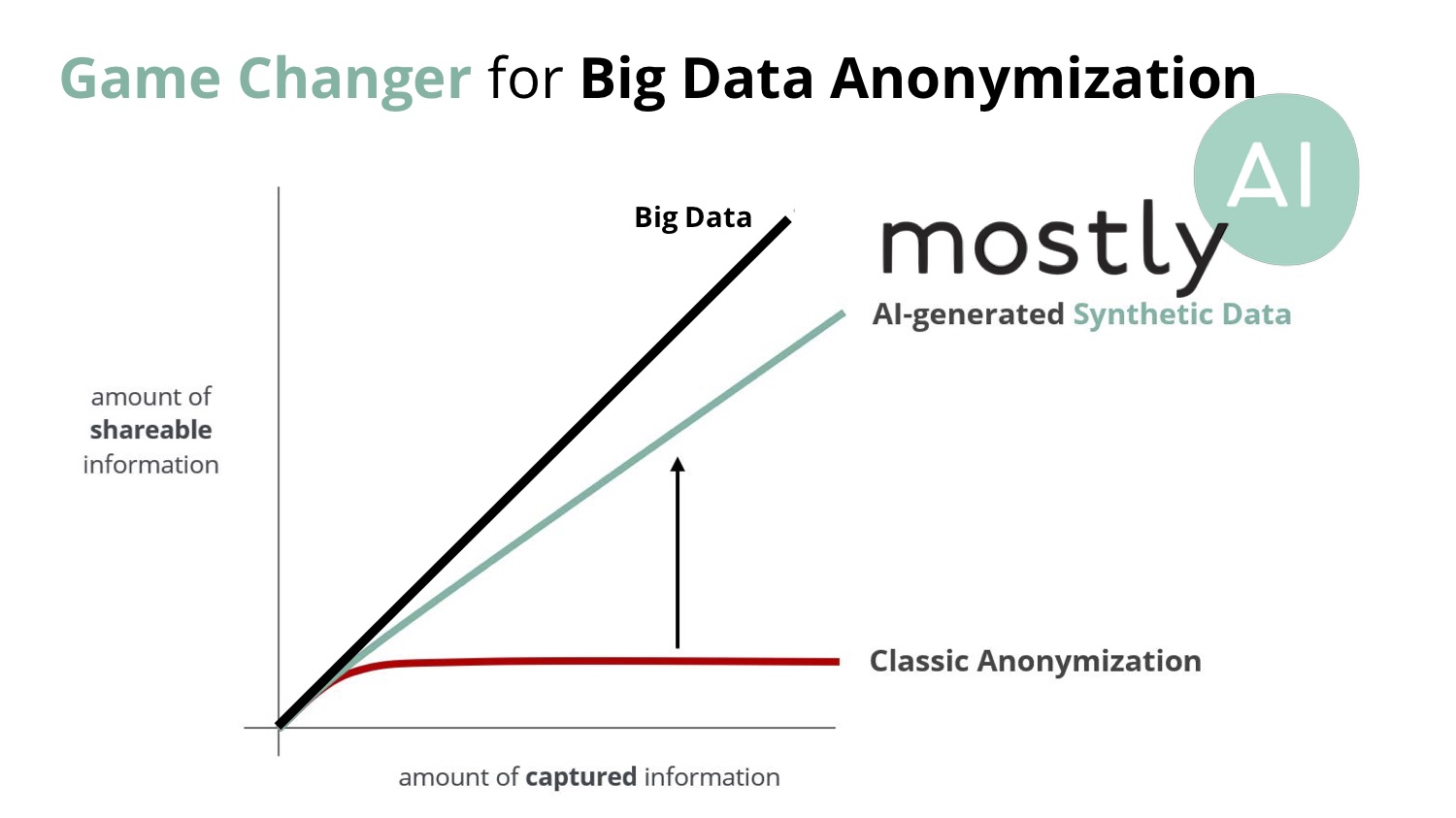
従来の匿名化データでは、ビッグデータの増加に追いつけていなかったが、Mostly AIのシンセテックデータ作成システムが普及することで、流通可能なデータは大幅に増加する。
つまり、2020年までに20兆円を超えるといわれるデータ分析市場がさらなる拡大を見せる可能性があるということだ。

──アレクサンドラ
「データ関連市場は今後も拡大を続けることは明らかですが、データ保全のようなリスク回避に注ぎ込まれる投資から、データの売買のような流通にかかる投資に移り変わる未来を私たちは描いています。また、データの流通によってスタートアップや既存企業の競争力が上がり、自由度の高いビジネスが生まれていくのではないかと思います」

(制作:Ledge.ai 執筆:小出拓也)


