HP Tech&Device TV 内のコンテンツを検索します。
2019.08.23
JapanTaxiの配車キャンセルによる損失を減らすための機械学習とその運用






「JapanTaxi」アプリは、2011年12月にサービスを開始し、シリーズ累計ダウンロード数800万ダウンロードの国内No.1タクシーアプリだ。アプリ1つでタクシーの手配から予約、タクシー料金の支払いまで可能だ。
機械学習やディープラーニングなどいわゆるAIを活用する企業は増えてきた。しかし、システムとして安定的に運用する機械学習基盤は、開発方法や運用の仕方を含めて模索中であり、それはJapanTaxiも同様である。
JapanTaxi 次世代モビリティ事業部の渡部 徹太郎氏は、データエンジニアとして、どのようにして本番環境で機械学習を安定して動かすかにフォーカスした講演を、企業研究所による合同研究発表カンファレンス「CCSE(Conference on Computer Science for Enterprise)」にて行った。
キャンセルによる損失を、事前予測で削減する
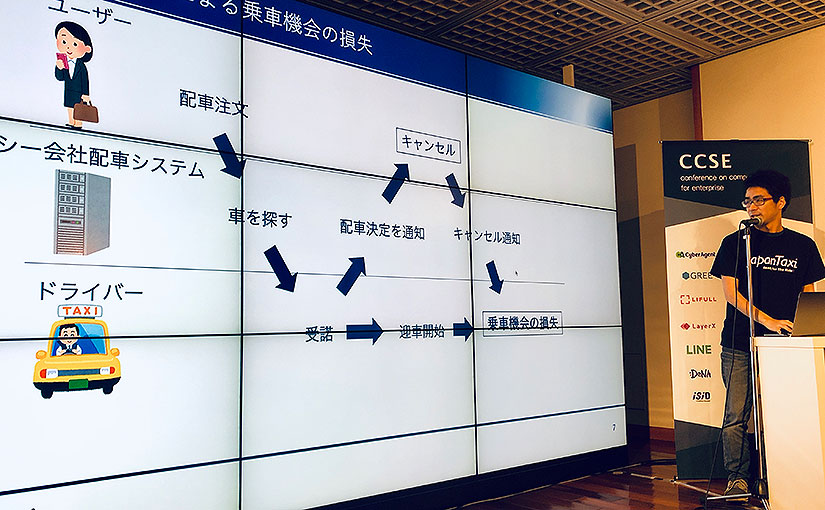
「JapanTaxi」アプリには、タクシーを呼ぶ「配車」機能がある。しかし、ユーザーが待ちきれずにキャンセルしてしまうケースは少なくない。その際に、タクシーが無駄に配車されてしまうという課題があった。
これはユーザーが5分程度でタクシーが来るだろうと期待して配車依頼したものの、依頼後にアプリに表示される配車時間が10分を超えたときなど、ユーザの期待時間と実際の配車時間のギャップが大きい時に起こる傾向があった。
そこで開発されたのが、ディープラーニングを使ったタクシーの到着時間を予測するシステムだ。
ユーザーは、予測されたタクシーの配車到着時間から、キャンセルするかどうかを判断できる。この機能により配車依頼数を維持したまま、配車キャンセル率だけを下げることに成功した。つまり、タクシー会社の損失を軽減できたのだ。
到着時間予測システム運用上の課題と解決策

データサイエンティストがモデルを作り終えた後は、システムを運用する必要がある。JapanTaxiが直面した課題は、以下3つだ。
- 再現できないシステム
ワークフローがJupyter Notebookで書かれている。学習データがバージョンが管理されていない。 - 精度評価がされないモデル
どういう状態が正しいモデルか定義されていない。精度モニタリングがなく、経年劣化に気付けない。 - セーフティネットのない本番システム
リリースは手動で一括切り替え。エラー件数監視なし。応答速度監視なし。
それぞれの課題に対しての対応策は下記の通りである。
- 処理を再実行可能な形に細分化し、運用に必要な機能を付加してバッチ処理化。加えて、学習データのバージョン管理を行った。
- 毎週最新のデータでモデルの予測精度がしきい値を超えていないかチェックすると共に、予測の分布を目視で監視した。
- Jenkinsで自動リリースジョブを作成するとともに、10%だけ新しいモデルに置き換え、問題がない場合は全てを新しいモデルでリリースする「カナリアリリース」を導入した。
開発したものの、運用や保守を考慮しなかったことで起こる問題がある。とくに、機械学習、ディープラーニングを使ったシステムでは顕著だろう。JapanTaxiではタクシービッグデータ解析のためのデータサイエンティストとデータエンジニアを今後増員する予定だそうだ。
AIシステムを開発する企業は、課題が起きる前に予防する、起きた後に解決するという意味でも、内部でデータエンジニアを抱えることは必須になりそうだ。
![]()
(制作:Ledge.ai 執筆:Ledge.ai編集部)


