掲載日:2020/11/20




文字列メトリクスを利用したマルウェアキャンペーンの追跡
※ 本ブログは、2019年12月6日にBromium Blogにポストされた Tracking Malware Campaigns Using String Metrics の日本語訳です。
イントロダクション
効果的なネットワークセキュリティ監視の要件は状況認識で、これはネットワーク内の良性の活動と悪意のある活動を理解することを意味します。状況認識を行うことで、ネットワークの防御者は通常の行動のベースラインを確立することができ、悪意のある可能性のある異常な活動を調査するためのアナリストの能力を解放することができます。状況認識の1つの側面として、フィッシングキャンペーンなどの潜在的な脅威と実際の脅威を時系列で認識することが挙げられます。データを可視化してダッシュボードで表示することは、ネットワークが直面している脅威を一目で理解するための有用な分析手法です。この記事では、文字列メトリクスをメールログに適用して潜在的なマルウェアキャンペーンを特定し、その結果を類似性リンクチャートとして可視化する方法を説明します。また、類似度リンクチャートを生成するための付随的なツールである graph_similiar_strings.py もリリースしています。[1]
パターン認識
人間の脳は視覚的・聴覚的なパターンを認識する能力に優れています。[2] 例えば、同じキャンペーンのフィッシング・メールは、件名、添付ファイル名、ヘッダー情報、メッセージ・テキストに類似性があるため、アナリストはそれを見抜くことができます。問題は、アナリストの時間が限られており、メールログは非常にノイズが多く、アナリストがすべてのメールログを調査することは不可能であるということです。その結果、セキュリティチームはメールログに含まれる潜在的に悪意のある活動のパターンを見逃してしまい、状況認識にギャップが生じてしまいます。解決策としては、パターン特定プロセスを自動化することです。文字列メトリクスは、この目的のために使用できるツールの 1 つです。
文字列メトリクスとは?
文字列メトリクスまたは文字列類似度関数は、2 つの文字列がどれだけ似ているかを測定するものです。[3] 距離のしきい値を設定することで、文字列メトリクスを使用して、類似しているが異なる文字列を識別することができます。これは、攻撃者が分析対象の文字列の一部の文字を変化させたとしても、同じキャンペーンの2つのメール間の距離は小さい可能性が高いため、メールログからパターンを発見するのに便利な特性です。
文字列メトリクスは複雑なテーマで、ここでは一つの問題に適用することで何が可能かの表面をスクラッチするだけです。文字列メトリクスの仕組みや他のシナリオへの応用についてもっと知りたい方は、記事の最後にいくつかのリソースをリストアップしました。このプロジェクトでは、3つの文字列メトリクスを比較しました。Jaccard、Hamming、Levenshteinです。それぞれのメトリクスは、比較する文字列を含む2つのセット(例:AとB)を必要とします。
ここでは、Michaël MeyerのPython距離ライブラリを使用して、各メトリクスがどのように動作するかを説明するための簡単な例を示します。[4]
Jaccard 距離
2つの文字列の間のJaccard 距離は、集合Aと集合Bの交点の大きさを和の大きさで割ったものです。例えば、文字列 "hello "と "world "のJaccard 距離を求めるには、まず結合後の集合の要素数を数えて(9)、共有されている要素の数、つまり交点の数を引くことで、結合の大きさを計算します。この場合、要素 "l "と "o "は共有されているので、和は7(9 - 2 = 7)になります。最後に、交点を和で割ります(2 / 7 = 0.29)。Jaccard 距離は素早く計算でき、正規化された結果が得られます(つまり、0は文字が共有されていないことを意味し、1はすべての文字が共有されていることを意味します)。Jaccard の欠点は、文字の順番や重複に敏感ではないことです。
>>>> import distance
>>>> index = distance.jaccard('hello', 'world')
>>> 1 - index
0.2857142857142857
Hamming 距離
2つの文字列の間のHamming 距離は、異なる文字の総数です。例えば、"hello "と "world "の間のHamming 距離を求めるには、文字列の中で異なる文字を数えます(4)。Hamming は素早く計算できますが、同じ長さの文字列しか比較できないという大きな欠点があります。
| 位置 | 0 | 1 | 2 | 3 | 4 |
| 文字列 A | h | e | l | l | o |
| 文字列 B | w | o | r | l | d |
| 違い? | 真 | 真 | 真 | 偽 | 真 |
>>> import distance
>>> distance.hamming('hello', 'world')
4
Levenshtein 距離
Levenshtein 距離とは、ある文字列を別の文字列に変えるのに必要な最小の文字操作数のことです。この例では、"hello "と "world "の間のLevenshtein 距離を求めるために、一方を他方に変えるのに必要な文字操作を数えます(4)。3つの指標のうち、Levenshtein 距離は計算に最もコストがかかりますが、文字の順番や重複に敏感で、異なる長さの文字列を計算できるという点では、Jaccard やHamming の欠点はありません。
| 位置 | 0 | 1 | 2 | 3 | 4 |
| 文字列 A | h | e | l | l | o |
| 文字列 B | w | o | r | l | d |
| 操作 | 置換 | 置換 | 置換 | None | 置換 |
>>> import distance
>>> distance.levenshtein('hello', 'world')
4L
総合的に判断して、ダッシュボードの要件に最も適した文字列メトリクスとして Levenshtein を選択しました。ダッシュボードはリアルタイムではなく定期的に更新されるため、速度は気になりません。速度が重要な場合は、別の文字列メトリクスがより適切であることがわかります。また、計算する最大文字列長差に制限を設定することで、Levenshtein 距離の計算を高速化することもできます。
どの文字列メトリクスを利用するかを決定できたので、次のステップではダッシュボード用のデータを収集してフィルタリングします。
メールデータの収集と絞り込み
2019年現在、マルウェアの初期アクセスベクターとして最も一般的なのはEメールであり、Eメールを媒介とする脅威の追跡に特別な焦点を当てるべきであることを意味します。[5] 最初のタスクは、分析するためのEメールログを取得することです。企業の環境では、EメールログはEメールゲートウェイ、またはBromium Secure Platformによって隔離されたEメール脅威から取得することができます。ここでは、潜在的に悪質なメールキャンペーンを特定することに関心があるため、送信者と受信者が同じドメインにあるメールなど、無関係なデータをフィルタリングして除外することができます。多くのフィッシングメールは、送信者アドレスを偽装してより信頼性の高いルアーを作成しているため、データをフィルタリングする前に、Sender Policy Framework (SPF)、DomainKeys Identified Mail (DKIM)、Domain-based Message Authentication, Reporting, and Conformance (DMARC)の情報を確認することで、メールの送信元がお客様のドメインであることを確認します。[6][7][8]
また、珍しいファイル拡張子などの特異なデータをハイライトすることで、類似性リンクチャートを充実させることもできます。隔離されたEメール脅威に関するBromiumのデータは、Eメールで配信されるマルウェアのファイル拡張子に多くの多様性があることを示唆しています。たとえば、2019年11月には、当社の顧客全体で、Eメールを媒介とする脅威のための47のユニークなファイル拡張子が観測されました。最も一般的なファイル拡張子はMicrosoft Officeに関連したものですが、マルウェアを含むひどく変わったなアーカイブ形式(例:ARJ、UUE、Z)も多く見られました。この観察に基づき、これらのフォーマットは悪意のある可能性が高いため、一般的ではないフォーマットを強調表示することができます。
| 7Z | PIF | XLSB |
| ACE | PNG | XLSM |
| ARJ | PPA | XLSX |
| CAB | R00 | XZ |
| DAT | R01 | Z |
| DOC | R02 | ZIP |
| DOCM | R11 | ZIPX |
| DOCX | R12 | |
| EXE | R15 | |
| FDS | R20 | |
| G_ | R24 | |
| GZ | R29 | |
| HTM | RAR | |
| HTML | RTF | |
| IMG | SCR | |
| ISO | TAR | |
| JAR | TXT | |
| JPG | UUE | |
| LZH | XLAM | |
| XLS |
表1 - メールで配信されたマルウェアのファイル拡張子(2019年11月)
graph_similar_strings.pyの紹介
文字列メトリクスを使用してメールログを分析し、結果を可視化する方法を実証するために、graph_similar_strings.pyというPythonスクリプトを公開しました。[1] これは文字列のリストを読み取り、選択した文字列メトリクスと距離しきい値に基づいて類似した文字列を一緒にクラスタリングするリンクチャートを生成します。
このスクリプトは、ファイル名や件名行などの類似した文字列をクラスタリングして、悪意のある可能性があるメールキャンペーンの状況認識を管理するためのダッシュボードを作成するために使用できます。スクリプトを使用するには、文字列のリストを含むテキストファイルを指定します。デフォルトでは、スクリプトはグラフ生成および可視化ライブラリNetworkXとGraphvizを使用して画像としてエクスポートされたDOTファイルを出力します。[9][10] GraphvizがPATHにある場合、スクリプトはSVG(推奨)またはPNG画像にエクスポートします。まず、お使いのネットワークからサンプルデータセットに対してスクリプトを実行し、距離のしきい値をお使いの環境に合わせて調整することをお勧めします。
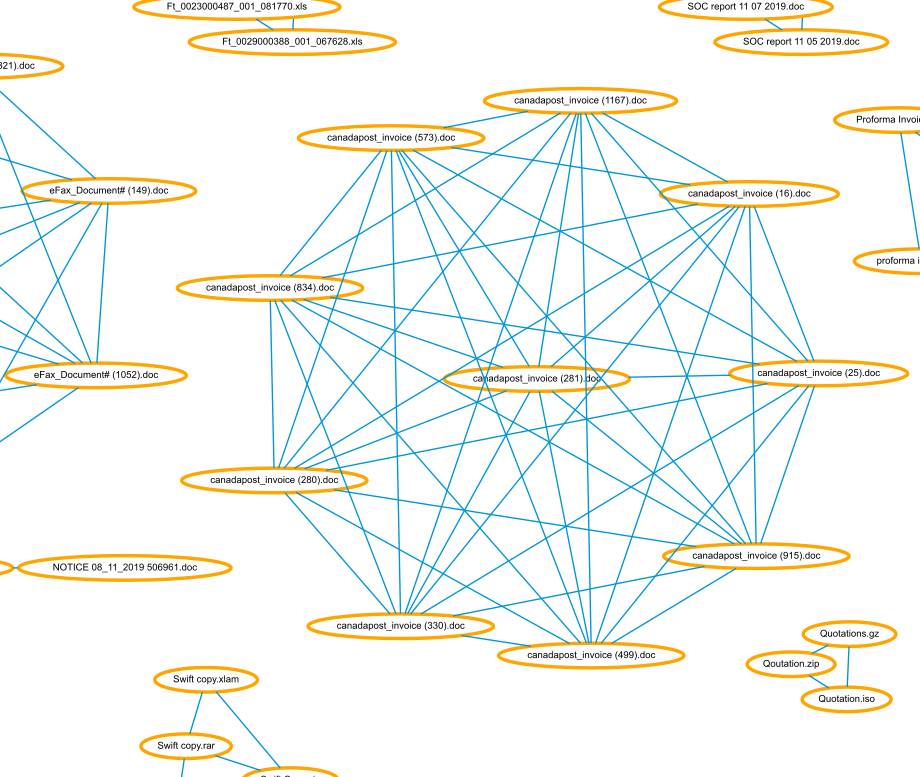 図1 - 類似したファイル名がクラスタリングされている graph_similar_strings.py で生成した添付ファイル名の類似度リンクチャート
図1 - 類似したファイル名がクラスタリングされている graph_similar_strings.py で生成した添付ファイル名の類似度リンクチャート
実践例 - 類似ファイル名を使用したマルウェアキャンペーンの追跡
図2から4は、3ヶ月間(2019年9月~11月)のEmotetのマルスパムキャンペーン活動のサブセットの展開を示すファイル名類似度リンクチャートです。各ノードは、距離のしきい値を満たした他のファイル名に辺連結されたユニークなファイル名です。定期的にリンクチャートを生成することで、マルウェアキャンペーンの規模と性質を一目で理解し、メールを媒介とする脅威が発生する際の状況認識を高めることができます。
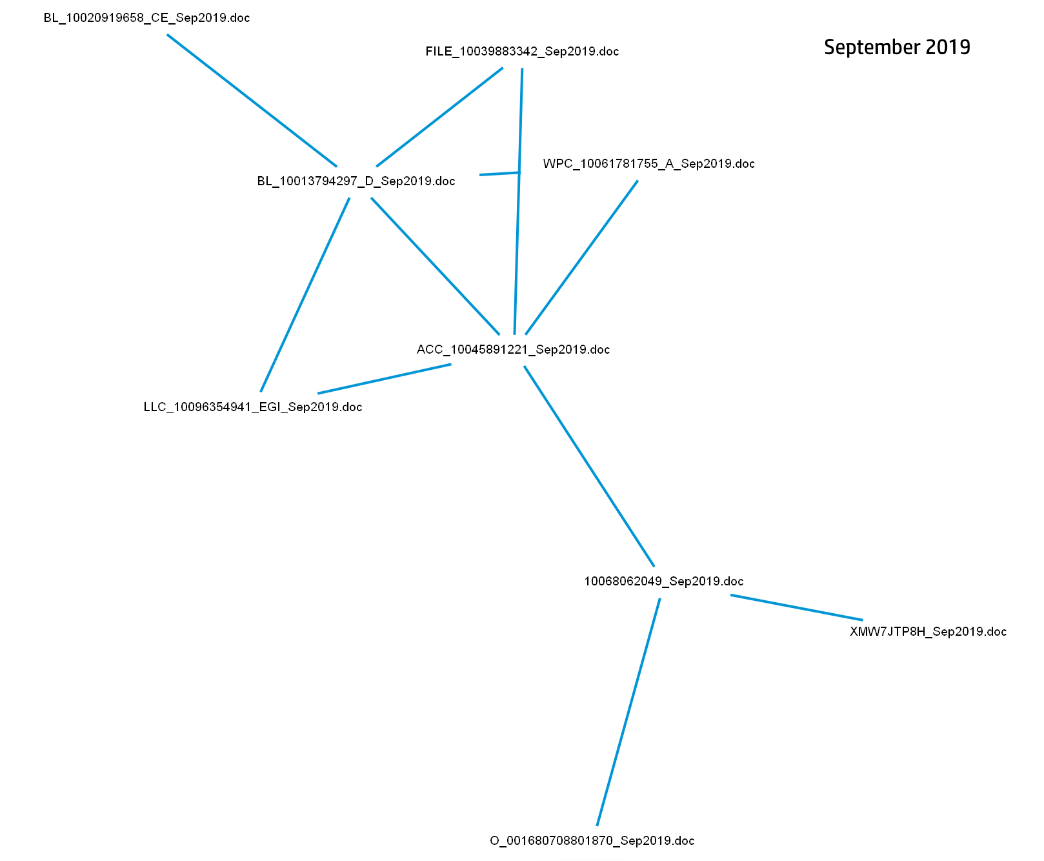 図2 - 2019年9月(1ヶ月目)のEmotetマルスパムキャンペーンのファイル名類似度リンクチャート
図2 - 2019年9月(1ヶ月目)のEmotetマルスパムキャンペーンのファイル名類似度リンクチャート
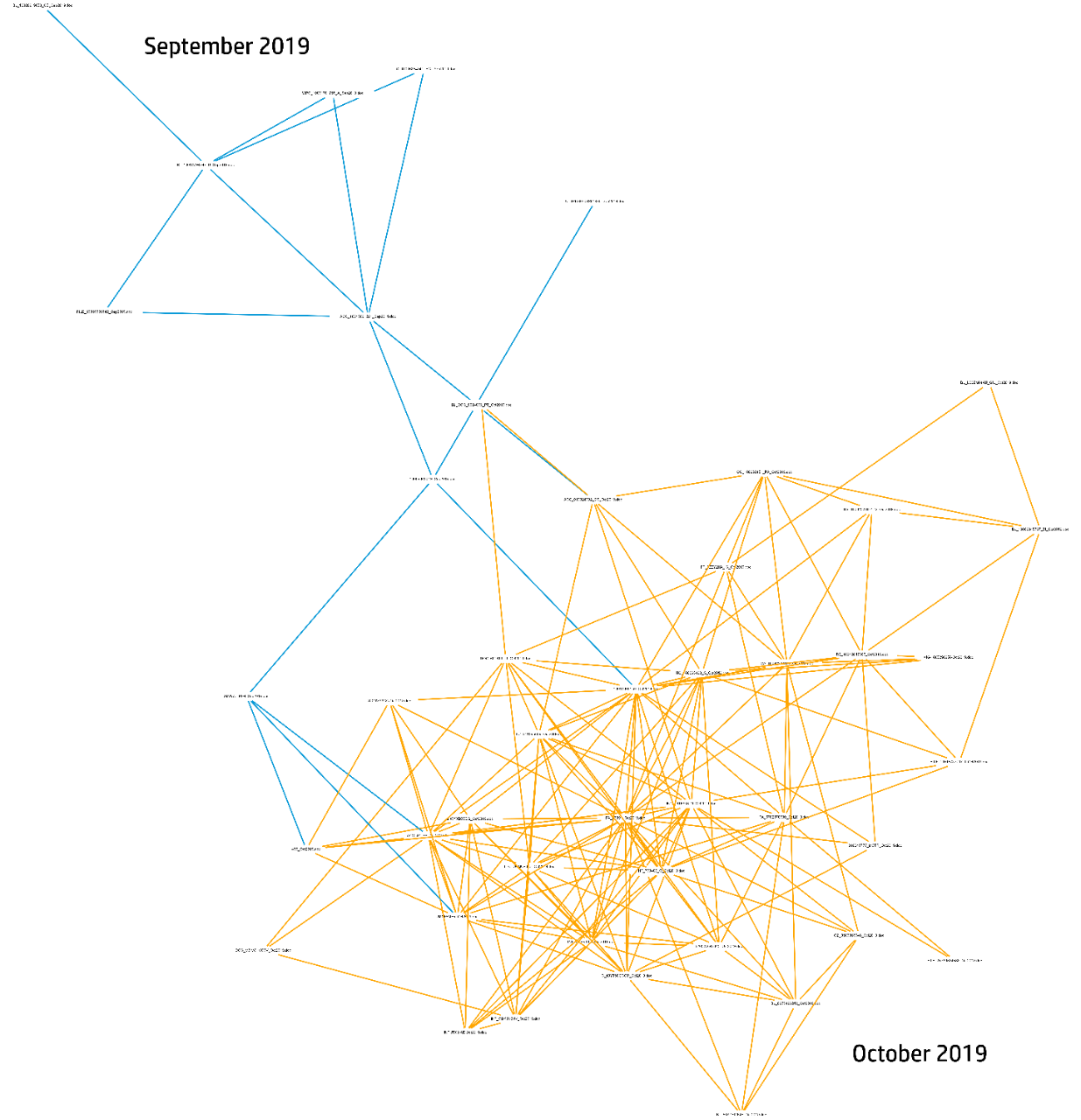 図3 - 2019年10月(2ヶ月目)のEmotetマルスパムキャンペーンのファイル名類似度リンクチャート
図3 - 2019年10月(2ヶ月目)のEmotetマルスパムキャンペーンのファイル名類似度リンクチャート
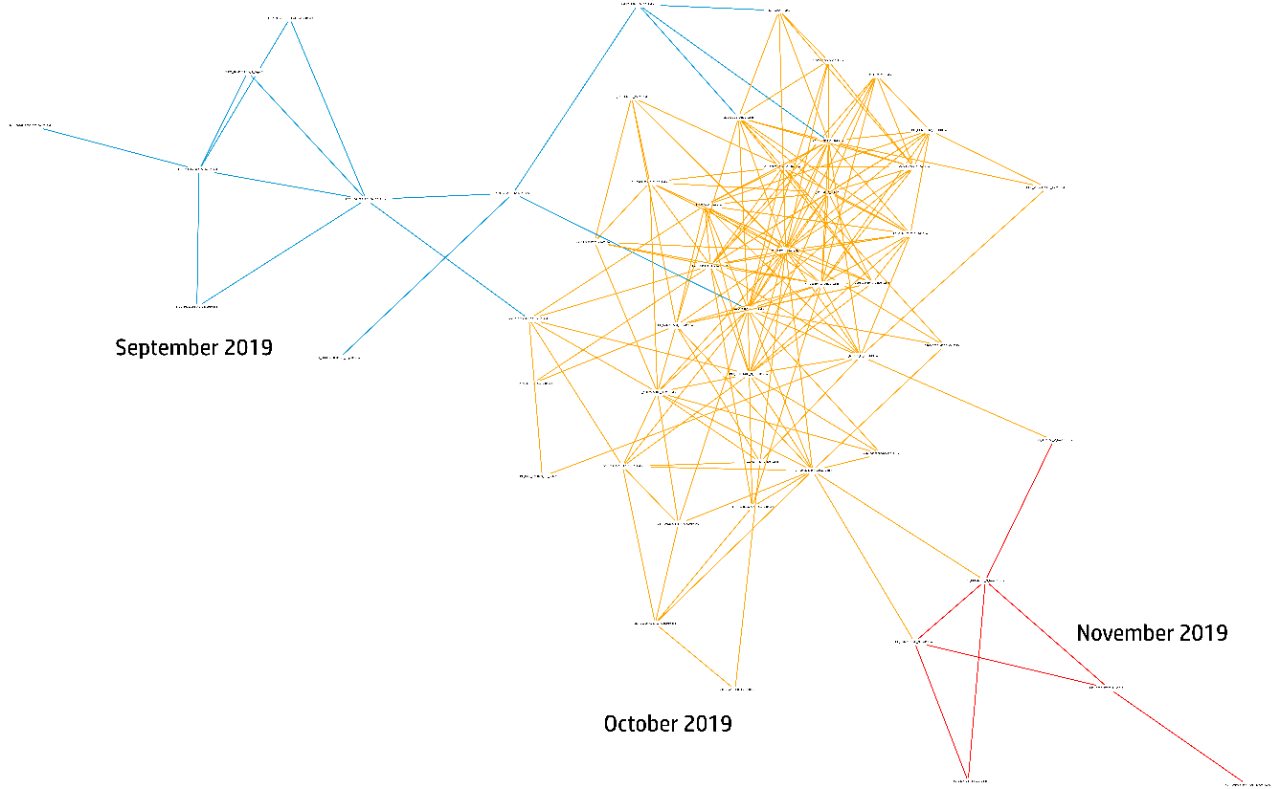 図4 - 2019年11月(3ヶ月目)のEmotetマルスパムキャンペーンのファイル名類似度リンクチャート
図4 - 2019年11月(3ヶ月目)のEmotetマルスパムキャンペーンのファイル名類似度リンクチャート
参考文献
文字列メトリクスは、他の検知シナリオでも使用することができます。例えば、文字列メトリクスは、タイプミスのあるドメイン名や、正規のシステムファイルに酷似した名前が付けられた悪意のあるファイルを識別するために使用できます。[11] 詳細については、以下のリソースをお勧めします。
- Metcalf, Leigh and Casey, William, Cybersecurity and Applied Mathematics (Cambridge, MA: Syngress, 2016)
- Collins, Michael, Network Security Through Data Analysis (Sebastopol, CA: O’Reilly, 2017), 2nd Ed.
- Saxe, Joshua and Sanders, Hillary, Malware Data Science (San Francisco, CA: No Starch Press, 2018)
リファレンス
[1] https://github.com/cryptogramfan/Malware-Analysis-Scripts/tree/master/graph_similar_strings
[2] Mattson, Mark P. “Superior pattern processing is the essence of the evolved human brain.” Frontiers in neuroscience vol. 8 265. 22 Aug. 2014, doi:10.3389/fnins.2014.00265
[3] https://en.wikipedia.org/wiki/String_metric
[4] https://pypi.org/project/Distance/
[5] Verizon, 2019 Data Breach Investigations Report, p. 13, https://enterprise.verizon.com/resources/reports/2019-data-breach-investigations-report.pdf
[6] https://en.wikipedia.org/wiki/Sender_Policy_Framework
[7] https://en.wikipedia.org/wiki/DomainKeys_Identified_Mail
[8] https://en.wikipedia.org/wiki/DMARC
[9] https://networkx.github.io/
Author : Alex Holland
監訳:日本HP

