【完全攻略】今さら聞けないRAG(検索拡張生成)とは?
2025-02-27

「RAG(ラグ)って最近よく聞くけど、一体何なんだろう?」「AIをビジネスに活用したいけど、RAGって本当に役立つの?」
そんな疑問をお持ちではありませんか?
生成AIツールの進化が加速する今、RAG(Retrieval Augmented Generation:検索拡張生成)は、企業現場での活用可能性を大きく広げる技術として、注目を集めています。しかし、その仕組みや具体的な活用方法を理解している方は、まだ少ないかもしれません。
そこでこの記事では、RAGの基本概念から、そのメリット・デメリット、導入方法、精度を高めるためのテクニック、そして未来のトレンドまで、徹底的に解説します。この記事では、RAGの仕組みから活用事例まで網羅的に解説します。
ライター:國末拓実
編集:小澤健祐
今さら聞けないRAG(検索拡張生成)の基本
まずは、RAGとは何か、その基本的な概念から詳しく見ていきましょう。
RAGとは何か
RAG(Retrieval Augmented Generation:検索拡張生成)とは、大規模言語モデル(LLM)が、外部の知識ベース(データベース、文書、ウェブサイトなど)から関連情報を取得し、その情報を基に回答を生成する技術です。
従来のLLMは、学習済みのデータに基づいて回答を生成するため、最新の情報や、企業独自の情報など、特定のドメインに特化した情報に対応するのが難しいという課題がありました。しかし、RAGを活用することで、LLMは常に最新の情報を参照し、より正確で信頼性の高い回答を提供できるようになったのです。
RAGとファインチューニングの違い
LLMに追加情報を与えるという話題として、「ファインチューニング」という言葉を聞いたことがあるかもしれません。この2つには下記のような違いがあります。
| 項目 | ファインチューニング | RAG |
|---|---|---|
| 初期コスト | 高い(データ準備・計算リソースが必要) | 中程度(インフラ構築が必要) |
| 運用コスト | 継続的な再トレーニングが必要 | データ更新と検索システムの維持 |
| 導入スピード | 遅い(トレーニング期間が長い) | 速い(外部データの活用が可能) |
| 精度 | 高い(ドメイン特化) | 中程度(外部データに依存) |
| 柔軟性 | 低い(新しいデータへの対応が遅い) | 高い(リアルタイムに更新可能) |
- ファインチューニング:事前学習済みのLLMを、特定のタスクやデータセットに適応させるための学習プロセスです。
- RAG:LLMが回答を生成する際に、外部の知識ベースを参照する技術です。
つまり、ファインチューニングはLLM自体を学習させ、RAGは回答を生成する際にLLMに情報を与えるという違いがあります。ファインチューニングは、LLMを特定の領域に特化させる場合に有効ですが、RAGは、LLMを最新情報や特定のデータソースに対応させる場合に有効です。
RAGの仕組み
RAGは、大きく分けて、以下の3つのステップで動作します。
- 検索:質問(プロンプト)に基づき、外部の知識ベースから関連情報を検索します。
- 拡張:検索された情報を、LLMの入力として適切な形式に変換します。
- 生成:変換された情報を基に、LLMが回答を生成します。
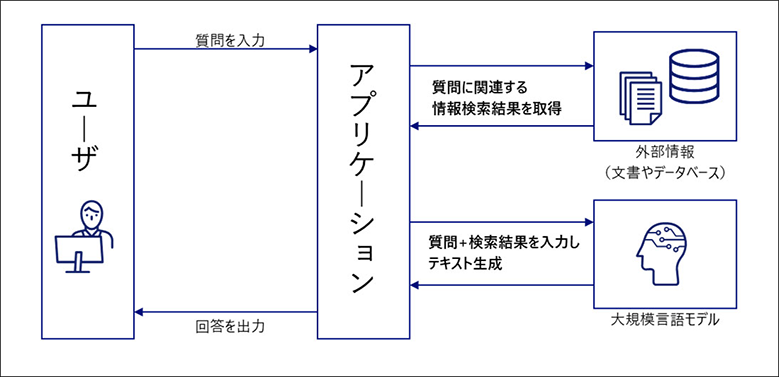
RAGを構成する主要要素
RAGは、以下の主要な要素から構成されています。
- 検索モデル:質問(プロンプト)に基づいて、外部の知識ベースから関連情報を検索する役割を担います。このモデルには、キーワード検索、ベクトル検索、セマンティック検索など、様々なアルゴリズムが利用されます。
- 生成モデル:検索された情報を基に、回答を生成する役割を担います。このモデルには、ChatGPTなどのLLMが用いられます。
- ベクトルデータベース:外部の知識ベースを、AIが理解しやすい数値データ(ベクトル)に変換して格納するデータベースです。これにより、AIは大量の情報を高速に検索できるようになります。
RAGの4つのメリット
RAGには、従来のLLMをそのまま活用するやり方にはない、様々なメリットがあります。ここでは、ビジネスにおいて特に重要な4つのメリットを紹介します。
①ハルシネーションが発生しづらい
RAGの最大のメリットの一つは、ハルシネーション(誤った情報を生成してしまう現象)が発生しづらい点です。従来のLLMは、学習済みのデータに基づいて回答を生成するため、学習データにない情報や、誤った情報が含まれている場合、誤った回答を生成してしまう可能性がありました。しかし、RAGは常に追加された外部データベースから参照するため、回答の信頼性が大幅に向上します。
②より特化した活用に向いている
RAGは、特定のドメインに特化した知識を必要とする業務に最適です。
- 専門知識が必要な業務:医療、法律、金融など、専門的な知識や最新の情報が求められる分野で、RAGを活用することで、AIはより正確で専門性の高い回答を生成できるようになります。
- 社内データの活用:また、自社の社内規程や過去の事例などのデータを取り込むことで、社内業務に特化したAIシステムを構築することが可能です。例えば、社内FAQの回答や、営業資料の作成などにRAGを活用することで、業務効率を大幅に向上させることができます。
③モデルサイズや学習コストが削減される
RAGは、LLM自体をファインチューニングする必要がないため、モデルサイズや学習コストを削減できます。
- ファインチューニングを避けて実装できる:従来のLLMは、特定のドメインに特化させるために、大規模なデータセットでファインチューニングする必要がありました。しかし、RAGを活用することで、LLMは外部の知識ベースから必要な情報を取得するため、ファインチューニングの必要性が低くなり、学習コストを抑えることができます。
- リソースの節約:モデルサイズを小さく抑えることができるため、計算リソースを節約することができ、結果として導入・運用コストを抑えることができます。
④必要なプロンプトサイズが減少する
RAGを活用することで、必要なプロンプトサイズを減少させることができます。
- 検索による情報補完:RAGは、外部の知識ベースから関連情報を検索するため、プロンプトに詳細な情報を記載する必要性が少なくなります。例えば、「○○に関する情報を教えて」とだけプロンプトに入力すれば、AIが自動的に関連情報を検索し、詳細な回答を生成してくれるようになります。
- プロンプトエンジニアリングの負荷軽減:これにより、ユーザーは、よりシンプルなプロンプトで、高品質な回答を得ることができるため、プロンプトエンジニアリングの負担を軽減することができます。
RAGのデメリット
RAGは多くのメリットがある一方で、導入前に知っておくべきデメリットや課題も存在します。
精度を上げるためにはノウハウが必要
RAGの精度を最大限に引き出すためには、専門的な知識や経験が必要です。
- 適切な知識ベースの構築:外部の知識ベースの選定、適切な形式でのデータ格納、検索モデルの選定など、様々なノウハウが必要になります。特に、自社の業務に最適化された知識ベースを構築するには、試行錯誤を繰り返す必要があるでしょう。
- プロンプト設計の重要性:また、AIが適切な情報を検索し、正確な回答を生成するためには、知識をうまく引き出すための適切なプロンプト設計も重要になります。
データベースの維持管理コストがかかる
RAGは、外部の知識ベースを常に最新の状態に保つ必要があるため、データベースの維持管理コストが発生します。
- 定期的なメンテナンス:知識ベースの更新、誤った情報の修正、データの追加など、定期的なメンテナンスが必要です。特に、情報量が膨大になるほど、その維持管理は大変になります。
- セキュリティ対策:また、外部の知識ベースのセキュリティ対策も重要になります。特に、機密情報や個人情報を扱う場合は、他社に見られたり学習されないよう、セキュリティ対策を徹底する必要があります。
コスト増加
RAGは、通常のLLMを使用するよりも、計算コストが高くなる傾向があります。
- 検索処理のコスト:RAGは、LLMによる回答生成に加えて、外部の知識ベースを検索する処理も行うため、計算リソースを消費します。特に、大規模な知識ベースを扱う場合、コストが増加する可能性もあります。
- システムの複雑化:また、RAGの導入には、LLMの他に、検索モデルやベクトルデータベースなど、複数のシステムを組み合わせる必要があり、システム全体が複雑になる傾向があります。
このようなメリット・デメリットを鑑みたうえで、RAGを実装するかどうかを判断する必要があるのです。
RAGの導入方法
企業現場でRAGを導入する際には、以下の5つのステップを踏むと、よりスムーズに導入を進めることができます。
STEP1 業務プロセスの棚卸
まずは、RAGを導入したい業務プロセスを明確にするために、現状の業務プロセスを棚卸しします。
- 課題の特定:どの業務プロセスに課題があるのか、どこを効率化したいのかを明確にします。
- RAGの適性判断:RAGが、その業務プロセスの課題解決に役立つのかどうかを判断します。
STEP2 活用範囲の選定
次に、RAGの具体的な活用範囲を絞り込みます。
- 目的の明確化:RAGを何のために活用したいのか、具体的な目的を明確にします。例えば、顧客からの問い合わせ対応を自動化したいのか、社内FAQを充実させたいのかなど、具体的な目的を定めることが重要です。
- 対象業務の選定:特定の業務に絞ってRAGを導入するのか、広範囲に導入するのか、導入範囲を決定します。
STEP3 必要なデータの選定
RAGで活用するデータを選定します。
- データソースの特定:RAGに参照させるべきデータソース(社内文書、データベース、ウェブサイトなど)を特定します。
- データ形式の決定:収集したデータの形式(テキスト、PDF、画像など)を把握し、RAGで利用できる形式に変換できるかを確認します。
STEP4 データ形式のブラッシュアップ
社内データをRAGで活用するために、AIが探しやすい形としてデータの形式をブラッシュアップします。
- データクレンジング:データの誤字脱字や表記ゆれを修正し、データの品質を高めます。
- 構造化:RAGが理解しやすいように、テキストデータは構造化(例:見出し、段落など)することを推奨します。また、画像や動画などの非構造化データを活用する場合は、AIが理解できる形式に変換する必要があります。
STEP5 継続的なPDCA
RAGは、作成して終わりではなく、制度を高めていくために導入後も継続的な改善が必要です。
- 効果測定:RAGの活用状況を定期的に分析し、期待しているように動いているか効果を測定します。
- 改善:効果測定の結果に基づき、知識ベースの更新、RAGの設定調整、プロンプトの改善などを行います。
- 不足情報の収集:より広範囲な利用ができるよう、足りないデータを定期的に追加したり、古いデータを更新する必要があります。
RAGは運用コストがかかる側面も持っています。どの分野にRAGを活用するのか、誰がメンテナンスをするのかなどを最初に決めてから、導入することが重要です。
RAGの精度を高める方法
RAGの精度を高めるためには、以下の3つのポイントを意識することが重要です。
1:データを網羅的に用意する
RAGの精度は、外部の知識ベースの品質に大きく依存します。
- 網羅的なデータ収集:幅広い範囲のデータを収集し、RAGが参照できる知識を充実させます。データが偏っていると、AIが偏った回答を生成してしまう可能性があるため、偏りのないデータを収集することを心がけましょう。
- 最新データの維持:常に最新のデータを知識ベースに反映することで、RAGの回答精度を高く維持します。
2:AIが読みやすい形式に整える
AIがデータを効率的に読み込み、検索できるように、データ形式を整えることが重要です。
- 構造化:テキストデータは、見出し、段落、リストなど、AIが理解しやすいように構造化します。
- メタデータの付与:各データに、キーワードやタグなどのメタデータを付与することで、AIが関連性の高いデータを検索しやすくなります。
3:プロンプトを工夫する
プロンプトは、RAGを活用する上でも回答品質を大きく左右します。
- 具体的な指示:AIに対して、あいまいな指示ではなく、具体的な指示を与えることで、AIはより正確な検索を行い、狙い通りの回答を生成できるようになります。
- キーワードの活用:プロンプトに適切なキーワードを含めることで、AIは関連性の高い情報を検索しやすくなります。
ビジネスにおけるRAG活用事例
RAGは、様々なビジネスシーンで活用することができます。ここでは、具体的な活用事例を3つ紹介します。
事例1:カスタマーサポートにおけるRAG活用:FAQの自動生成、問い合わせ対応の効率化
RAGを活用することで、FAQを自動生成したり、顧客からの問い合わせに対して、AIが的確な回答を迅速に提示できるようになります。
- 社内データ活用:社内文書や製品マニュアルをRAGの知識ベースとして活用することで、AIは常に最新の情報に基づいた回答を生成できます。
- 担当者の負担軽減:これにより、カスタマーサポート担当者の業務負担を軽減し、より高度なサポート業務に集中させることができます。
- 顧客満足度の向上:また、顧客はAIによって、いつでも必要な情報を得ることができ、顧客満足度の向上にも繋がります。
例えばLINE WORKS株式会社は、RAGを活用したAIチャットボット「AI相談室」を顧客に展開、カスタマーサポートの強化を実現しました。
※出典 LINE WORKS
事例2:コンテンツ作成におけるRAG活用:記事作成、メール作成、レポート作成の効率化
RAGを活用することで、記事作成、メール作成、レポート作成など、コンテンツ作成業務の効率化を図ることができます。
- 情報収集の効率化:RAGは、インターネット上の情報だけでなく、自社が持つ様々なデータソースから情報を収集することができます。
- コンテンツ生成:AIが収集した情報を基に、文章の作成、要約、翻訳などを行うことができます。
- 担当者の負担軽減:これにより、コンテンツ作成担当者は、より創造的な業務に集中することができ、業務効率を大幅に向上させることができます。
例えば清水建設株式会社では、全従業員にRAGを活用した「法人GAI」を導入し、事前調査や企画のアイデア出し、文書生成、要約などの業務に対して生産性改善に取り組んでいます。
※出典 清水建設
事例3:情報検索におけるRAG活用:社内文書検索、市場調査
RAGを活用することで、社内文書や市場調査などの情報検索をより効率的に行うことができます。
- 情報検索の効率化:RAGは、キーワードだけでなく、文章の意味を理解し、関連性の高い情報を検索できます。これにより、ユーザーは、大量の情報の中から必要な情報に素早くアクセスできるようになります。
- 情報分析の効率化:RAGは、検索結果を要約したり、特定のテーマに関する情報を抽出したりする機能も備えているため、情報分析の効率化にも貢献します。
例えば横浜銀行と東日本銀行では、RAGを活用した「行内ChatGPT」を導入し、従業員の業務効率化と生産性向上を図る取り組みをしています。
※出典 横浜銀行
2025年を見据えたRAGのトレンドと展望
2025年以降、RAGはさらに進化し、ビジネスに不可欠な技術になると予想されます。ここでは、2025年を見据えたRAGのトレンドと展望を解説します。
既存のチャットボットとの連携が加速
RAGは、既存のチャットボットと連携することで、より高度な顧客対応を実現できるようになるでしょう。
- パーソナライズされた対話:RAGを活用することで、チャットボットは、顧客の過去の問い合わせ履歴や、購買履歴などを参照し、個々の顧客に合わせた、よりパーソナライズされた対話が可能になります。
- ユーザー満足度の向上:これにより、ユーザー満足度を向上させるだけでなく、チャットボットの対応範囲を広げることがより簡単にできるようになります。
このように、カスタマーサクセスや社内問い合わせ対応などの領域でのAI活用が加速していくことが予想されます。
マルチモーダルRAGの進化
今後は、テキストだけでなく、画像や動画、音声データなどを含む、より多様なデータを活用したマルチモーダルRAGが登場すると予想されます。
- 多様なデータソース:マルチモーダルRAGは、画像、動画、音声などの非構造化データを活用することで、より高度で詳細な情報をAIに理解させることが可能になります。
- 様々な業界での活用:これにより、医療画像診断、製造業での品質管理、小売業での顧客行動分析など、様々な分野でRAGの活用が進むでしょう。
AIエージェントとの統合査
RAGは、AIエージェントと統合されることで、より自律的で高度な業務遂行が可能になると予想されます。
- 業務自動化:AIエージェントは、RAGを活用して必要な情報を自動的に収集し、その情報に基づいて、顧客対応や、レポート作成などの業務を自動的に行うことができます。
- 業務効率化:これにより、業務プロセスを効率化し、人間の生産性を大幅に向上させることができるでしょう。
おわりに
この記事では、RAG(検索拡張生成)の基本概念から、そのメリット・デメリット、導入方法、精度を高めるテクニック、そして2025年を見据えた未来のトレンドまで、徹底的に解説しました。
RAGは、大規模言語モデル(LLM)の可能性を最大限に引き出し、ビジネスの現場におけるAI活用を大きく進化させる、まさに変革のエンジンです。
特に、SLM(Small Language Models)とRAGの組み合わせは、今後のAI技術の進化を語る上で、欠かすことのできない要素となるでしょう。SLMは、デバイス上での処理を可能にし、RAGと連携することで、どこでも、誰でもAIの力を活用できる未来を切り開きます。
RAGは、まだ発展途上の技術であり、今後も様々な課題に直面するでしょう。しかし、その可能性は無限大です。
※このコンテンツには日本HPの公式見解を示さないものが一部含まれます。また、日本HPのサポート範囲に含まれない内容や、日本HPが推奨する使い方ではないケースが含まれている可能性があります。また、コンテンツ中の固有名詞は、一般に各社の商標または登録商標ですが、必ずしも「™」や「®」といった商標表示が付記されていません。




