LM Studio徹底ガイド:RAG・API・MCPで社内AI最短構築
2026-01-22

ライター:倉光哲弘
編集:小澤健祐
はじめに
クラウドのAIサービス活用に際し、「社内データを外部に出したくない」「クラウド課金が不安」といった悩みを抱えていませんか。
本記事は、これらの課題に直面するIT・情報セキュリティ担当者向けに、完全ローカルで動作する大規模言語モデル(LLM)実行環境「LM Studio」を解説します。
2025年7月、LM Studio本体(アプリ/内蔵サーバー機能)は、企業・組織における商用利用が完全無料化されました。これにより「稟議の根拠が乏しい」という導入時の障壁が下がり、実運用へ移行しやすくなっています。
本記事では、RAG(検索拡張生成)やOpenAI互換APIを活用し、最短1日でセキュアな社内AIのPoC(概念実証)を完成させる手順を具体的なコード例とともに解説します。
ぜひ最後までお読みいただき、セキュアな社内AI環境の構築にお役立てください。
LM Studioの使い方:Windowsインストールと初期設定を3ステップで解説
本章では、LM Studioを Windows へインストールし、初期設定を完了するまでの手順を解説します。初心者でも迷わず実務利用を開始できるよう、以下の3点を押さえます。
- インストール前の前提条件と推奨スペック
- ダウンロードからモデル導入までの3ステップ
- チャット機能での動作確認と基本設定
それぞれ詳しく解説します。

インストール前の前提条件と推奨スペック
LM StudioはLLMがメモリ(RAM/VRAM)を大量に消費するため、Windows で安定して動作させるには特定のハードウェアスペックが必要です。特にVRAM容量は、モデルの応答速度といった体感速度に直結します。
推奨されるスペックの目安は、以下の通りです。
- CPU: AVX2対応x64(Intel 第10世代 / AMD Ryzen 3000 以降など)、またはARM版Windows
- RAM: 16GBを推奨します(8GBでは軽量モデル限定、32GB以上で快適)。
- GPU: VRAM 4GB以上を推奨します(NVIDIA / AMD 推奨、6GB以上が望ましいです)。
- ストレージ: SSDを推奨し、20GB~50GBの空き容量が必要です。
- OS: Windows 10 / 11(初回ダウンロード後はオフライン可)。
これらの条件を事前に確認しておけば、モデル導入から推論までを実用的な速度で運用できます。
参考:
System Requirements | LM Studio Docs
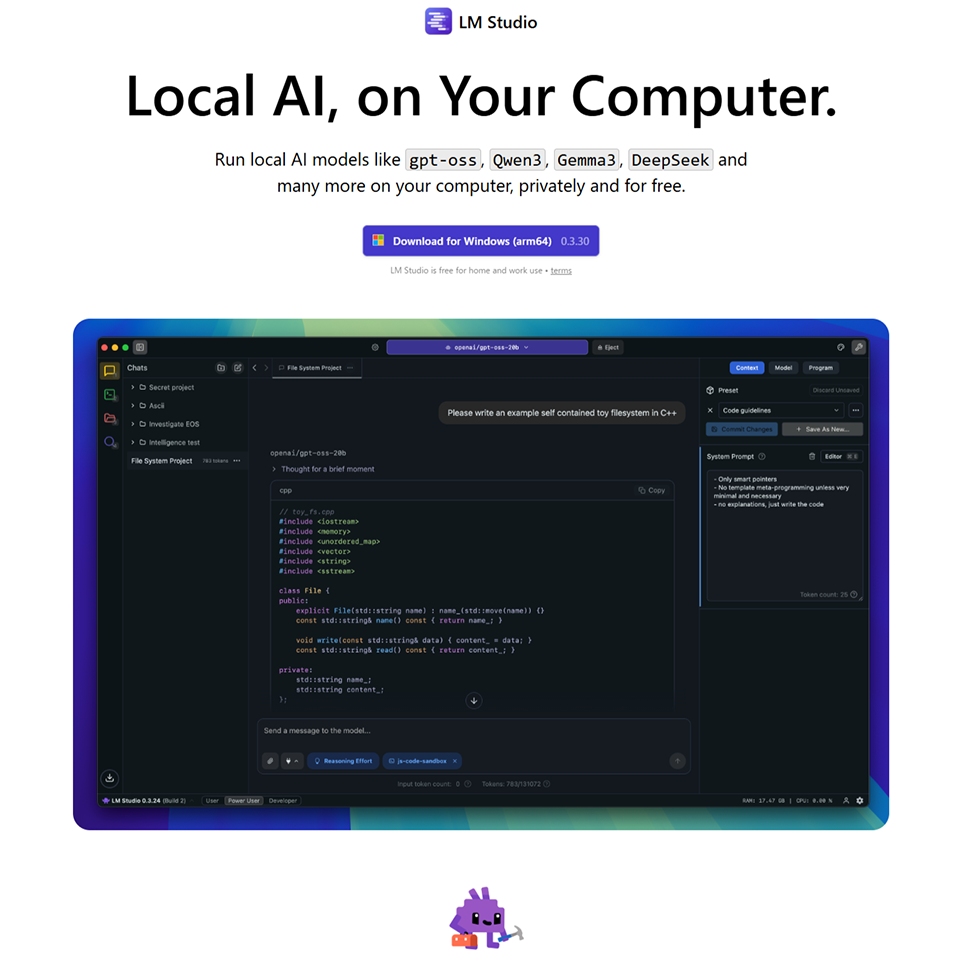
【3ステップ】LM Studioのダウンロードからモデル導入までの手順
LM Studioを Windows で使い始める手順を、3つのステップで解説します。初心者でも迷わず導入できるよう、UIの要点や設定のコツを整理しました。具体的には「ダウンロード」「モデル取得」「動作確認」の手順です。本セクションを読めば、短時間でローカルLLM環境を構築できます。
ステップ1:LM Studioのダウンロードとインストール
まず、LM Studio公式サイトから Windows 版インストーラー(.exe)を取得し、実行します。インストール時に特別な設定は不要です。基本的にはウィザードに従い、デフォルト設定のまま進めるだけで数分で完了します。
ダウンロード → 実行 → 確認画面での承認 → 完了
インストール後、アプリを起動するとメイン画面が開きます。モデルの保存先は設定から後で変更できるため、大容量モデルを別ドライブで管理することも容易です。
ステップ2:初期設定とモデル取得
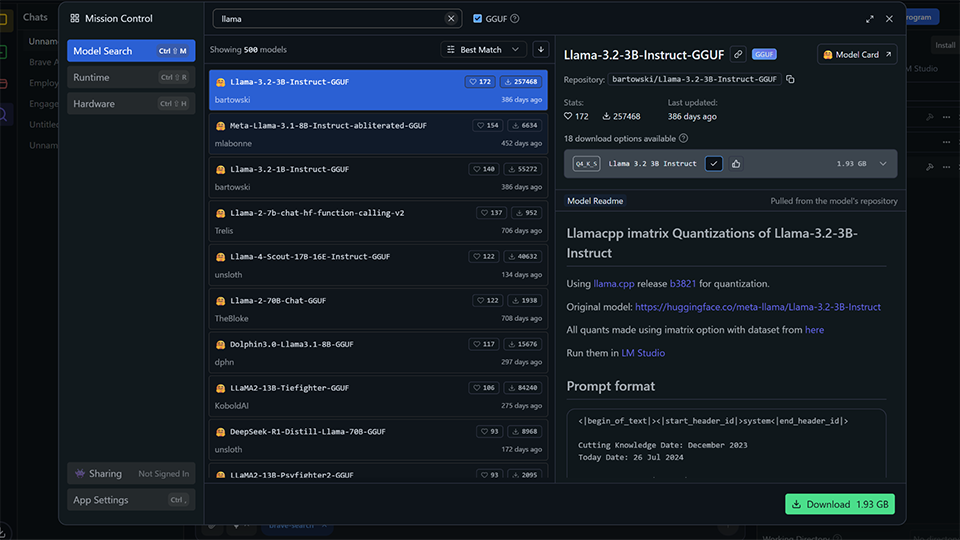
次に、アプリのHome画面(検索)から使用するLLMモデルを取得します。Hugging Face Hubと連携しており、GGUF形式の量子化モデルを直接選択できます。PCスペック(RAM/VRAM)に合わせ、3B~7Bの軽量モデルや、7B~14Bの標準モデルを選びましょう。
推奨(Recommended)タグを参考に、Q4などの量子化レベルを選択しダウンロードします。初回に最適なサイズを選べば、ストレージ容量と時間を節約できます。
ステップ3:チャットでの動作確認とパフォーマンス調整
モデル取得後、チャット画面(Chat)でモデルを読み込み、動作確認を行います。初回読み込み後は、短いメッセージを送り、応答が生成されるか確認しましょう。
設定(Configuration)からGPUオフロードを有効化すると、CPUのみで実行するより応答速度が大幅に向上します。翻訳や要約を試し、応答が遅い場合は、より量子化度の高いモデルを選ぶか、オフロードするレイヤー数を調整します。これにより、自身のPC環境で安定動作する設定を見つけられます。
ローカルドキュメントRAG(LM Studio)で始める社内ナレッジ活用
LM StudioのRAG機能で、PC内の機密文書を安全に活用しましょう。完全オフラインで動作し、高精度な回答を生成します。ファイル読み込みの基本操作から、回答精度向上のヒント、ローカル環境ならではのセキュリティ設計までを解説します。
RAGの位置づけとLM Studioの特性
LM Studioは、PC内の文書(.docx / PDFなど)を安全にAIで活用でき、基本的なRAG(検索拡張生成)機能を手軽に試せる点が強みです。処理がすべてPC内で完結し、「完全オフライン・テレメトリ(利用状況の送信)なし」で動作するため、機密情報が外部に漏れません。
チャット欄に.docxやPDF、TXTファイルを添付すると、文書の長さに応じて処理が自動で切り替わります。短い文書はそのまま「文脈」として扱われますが、長い文書はRAGによって関連する部分だけが参照されます。このRAG機能は、バージョン0.3.0以降「ベーシック(ナイーブ)」として組み込まれており、用途によっては精度調整(例:チャンク設計など)が必要な場合があります。
実務で使う際は、この「短文=全文参照」「長文=RAG参照」という自動切り替えの特性を理解し、ユースケース(利用場面)に応じて期待値を調整することが、安全な文書活用の第一歩として重要です。
参考:
Chat with Documents | LM Studio Docs
LM Studio 0.3.0 | LM Studio Blog
基本的な使い方(GUI)
LM StudioのRAG機能は、難しい設定を必要とせず、ドラッグ&ドロップだけで使い始められます。ファイル添付から質問、回答と引用の確認まで、基本的な操作は3つのステップで完了します。ここでは、その具体的な流れと注意点を解説します。
ステップ1:ファイルを添付する(対応形式と上限)
文書は、チャット欄の添付アイコン(クリップ)またはドラッグ&ドロップで追加できます。対応形式は “.docx”、PDF、TXTなどです。
1セッション(チャット)で扱えるファイルサイズは、合計30MBが上限です。これは総合計のため、ファイルを分割しても1セッション内で30MBを超えてアップロードすることはできません。ファイルを扱う際は、セッション合計で30MB以内に収まるよう計画してください。
ステップ2:自動で前処理(全文投入 or RAG切り替え)
ファイルが添付されると、LM Studioが文書の長さを判断し、自動で前処理を行います。ユーザーが手動で設定を切り替える必要はありません。
具体的には、短い文書は全文がそのままモデルのコンテキスト(文脈)に入力されます。一方、長い文書はRAG機能により、関連する断片(チャンク)のみが効率的に供給されます。これらすべての処理は、使用しているPCの内部で完結します。
この特長により、機密情報を含む文書であっても、ネットワークに接続していない隔離された環境で安全に利用できます。
ステップ3:質問する(回答と引用の見え方)
文書の読み込みが完了したら、チャット欄に質問を入力します。LM Studioが添付文書の内容に基づき、回答を生成します。
回答の末尾には、根拠となった出典(引用)の手掛かりが表示されることがあり、事実確認(ファクトチェック)に役立ちます。これをクリックすれば、キャッシュ(一時保存)された原文の該当箇所にアクセスできます。
期待した回答が得られない際は、質問を工夫すると精度が改善する場合があります。文書内の固有単語や関連キーワードを質問に含めると、モデルが文脈をより正確に捉えるためです。

参考:
LM Studio 0.3.0 | LM Studio Blog
Chat with Documents | LM Studio Docs
Offline Operation | LM Studio Docs
回答精度を上げる運用ヒント(必要に応じてSDKで拡張)
LM StudioのGUIに搭載されたRAG機能は、すぐに試せるよう基本的な実装(ベーシックRAG)が採用されています。
GUI上ではシンプルな操作性が優先されており、チャンク設計や取得数(top-k)などの詳細なパラメータを直接調整する機能は含まれていません。
もし、これらのパラメータを細かく制御したり、再ランカーを導入したりといった高度な調整が必要な場合は、PythonやTypeScript用のSDKを活用して独自の実装を行うことができます。
参考:
lmstudio-js (TypeScript SDK) | LM Studio Docs
セキュリティと運用(データ流とキャッシュ管理)
LM Studioは、機密情報を扱う上で重要なセキュリティを確保しており、データはPC外部に一切送信されません。アプリケーションが「完全オフライン」で動作し、利用状況を開発元に送信するテレメトリ機能もないためです。
文書の前処理、RAGによる検索、AIによる推論のすべてが端末内で実行されます。そのため、外部API(他社サーバー)を利用するサービスとは異なり、機密情報がPCの外に漏洩するリスクがありません。回答の根拠となる文書キャッシュ(一時データ)もローカルに保存され、チャット履歴の削除と同時に消去される仕組みです。
データがPC内に留まるため安全ですが、実務で運用する際は、使用モデルやアプリの更新、参照文書の版管理といった内部ルールを整備すると良いでしょう。
注意点と拡張の道筋(ナイーブRAGの限界を超える)
LM Studioの内蔵RAGは「ベーシックRAG」であり、高度な要求への対応には限界があります。
たとえば、文書種別に応じた最適なチャンキング(分割)、ハイブリッド検索、検索結果の再ランク(並べ替え)といった高度な技術は、標準機能に含まれていません。また、UI(操作画面)上ではPDFや.docxファイルが30MBまでに制限されるといった制約もあります。
まずは内蔵RAGで検証し、要件を満たせない場合はLM StudioのSDKを活用して独自のRAGを構築する、という拡張手順を検討するのが現実的です。
業務ツールと連携する:OpenAI互換APIとMCPの活用法
ローカルLLMを社内システムへ安全に組み込むには、OpenAI互換APIとMCPの活用が鍵です。APIは既存システムへの接続を容易にし、MCPは外部ツール連携の安全性を高めます。
本章では、ローカルLLMの連携について、以下の3点を解説します。
- OpenAI互換APIの実装方法
- MCP(Model Context Protocol)の活用と設定手順
- API・MCP連携に関するよくある質問
OpenAI互換API(/v1)の実装方法とエンドポイントの選び方
LM Studioが提供するOpenAI互換APIを利用すれば、既存のプログラムを最小限の変更でローカルLLMに接続できます。特に/v1/responsesエンドポイントは、会話状態の管理やストリーミング配信など、高度な制御を可能にします。
手順1:Base URL設定(http://localhost:1234/v1)
LM Studioのローカルサーバーを起動し、OpenAIクライアントのBase URLを http://localhost:1234/v1 に設定します。この設定により、既存のOpenAI SDKなどの接続先を差し替えるだけで、ローカルLLMを利用できます。動作確認は GET /v1/models で行えます。Webアプリから接続する際は、lms server start --cors を実行してCORS(オリジン間リソース共有)を有効にしてください。
手順2:用途で選ぶAPI
LM Studioは、互換性を重視した /v1/chat/completions と、独自機能(サーバー側の状態管理など)をサポートする /v1/responses の2種類のエンドポイントを提供しています。既存コードの移行しやすさや、実装したい機能に応じて選択します。それぞれの特徴は以下の通りです。
/v1/chat/completions(既存コードの最小改修・Function Calling中心)
既存のOpenAIクライアントコードを最小限の修正で移行したい場合に適しています。OpenAI公式と互換性の高い messages 配列形式を採用し、Function Calling(tools)にも対応しているため、移行が容易です。stream: true で応答の逐次出力も可能です。
/v1/responses(会話状態のサーバー管理・SSE/推論深度の制御)
会話状態をサーバー側で管理させたい場合や、LM Studio独自の機能を活用したい場合に使用します。messages 配列を毎回送る代わりに previous_response_id を渡すことで、会話を継続できます。また、stream: true によるSSE(サーバーセントイベント)出力、reasoning.effort での推論強度の制御、Remote MCP(オプトイン)による外部ツール利用もサポートしています。
手順3:選択API別の実装要点(Function Calling/前回ID連結/ストリーミング)
ツール呼び出しと会話の状態管理は、それぞれ異なるエンドポイントを使用します。
A. /v1/chat/completions:最小実装とFunction Calling
このエンドポイントは model と messages の送信が最小構成で、既存のOpenAI実装(SDKなど)から最小限の修正で移行できるように設計されています。Function Calling は tools にJSON Schemaを渡して使用し、逐次出力は stream: true で指定します。既存コードの流用やFunction Callingの実装に適しています。
C#による chat/completions 呼び出し例
// .NET 8 / トップレベルステートメント
using System.Net.Http;
using System.Text;
using System.Text.Json;
var http = new HttpClient { BaseAddress = new Uri("http://localhost:1234/v1/") };
var body = JsonSerializer.Serialize(new {
model = "YOUR_MODEL_NAME",
messages = new[] { new { role = "user", content = "社内FAQのテスト" } }
});
var res = await http.PostAsync("chat/completions",
new StringContent(body, Encoding.UTF8, "application/json"));
Console.WriteLine(await res.Content.ReadAsStringAsync());
// ※ クライアント側がAPIキー必須の場合、ダミーキー(例: "lm-studio")の付与が必要なケースがあります。
B. /v1/responses:継続会話とストリーミング
このエンドポイントの最小構成は model と input(文字列可)です。previous_response_id で会話を継続でき、サーバー側で状態管理できるのが特徴です。stream: true でSSE(ストリーミング)に対応するほか、Remote MCP(外部ツール)もアプリで有効化後に利用可能です。サーバーでの状態管理や独自機能を利用する場合に適しています。
cURLによる responses 呼び出し例
curl http://localhost:1234/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "YOUR_MODEL_NAME",
"input": "社内FAQのテスト"
}'
参考:
OpenAI Compatibility Endpoints | LM Studio Docs
Responses | LM Studio Docs
Tool Use | LM Studio Docs
MCP(Model Context Protocol)の活用と設定手順
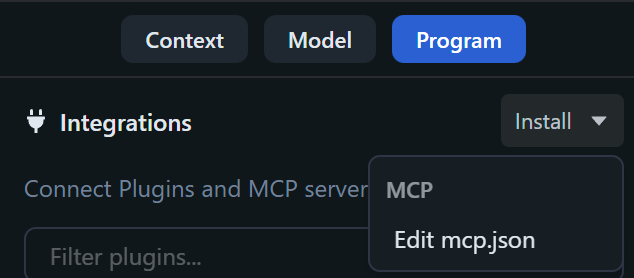
MCPは、LLMに外部ツールを安全に接続するための標準規格です。LM StudioはMCPのホストとして機能し、mcp.jsonファイルを通じて、利用する外部ツール(MCPサーバー)の登録や権限管理を行います。
手順1:mcp.jsonの配置と権限方針
MCPを利用するためmcp.jsonにサーバー情報を追記する際は、サーバーの信頼性確認が不可欠です。
MCPサーバーには、ローカルファイルへのアクセスや任意コード実行といった強力な権限を持つものがあるためです。
ファイルは「Program」 > 「Install > Edit mcp.json」から編集できますが、作業前に必ずサーバーの出所を確認してください。信頼できないサーバーは導入せず、必要最小限の権限のみを許可するように管理することが重要です。
手順2:サーバー追加と接続テスト
mcp.jsonにサーバー情報を追記した後、設定を有効化し、動作をテストします。実際にプロンプトを送信し、意図した通りに外部ツールが呼び出され、期待する応答が得られるかを確認する必要があるためです。例えば、Brave SearchのMCPを利用する場合、APIキー(環境変数 BRAVE_API_KEY)を設定し、npxやDockerでMCPサーバーを起動します。その後、「Integrations」タブで有効化します。まずは「Web検索を行い、その結果を要約する」といった一連の動作を試し、応答の品質を検証します。

手順3:監査ログと許可ドメインの設計
MCPは外部へのアクセス経路を開くため、セキュリティ対策として監査ログの運用が重要です。どのツールが、いつ、どのドメインにアクセスしたかを定期的に監査することで、不正な利用や情報漏洩のリスクを低減できます。許可するツールやアクセス先ドメインは明確に定義し、ホワイトリスト方式で管理します。MCPによっては大量のトークンを消費するものもあるため、モデルのコンテキストサイズ(扱える情報量)や社内ポリシーを考慮し、段階的に導入することが安全です。
参考:
Use MCP Servers | LM Studio Docs
lms server start | LM Studio Docs
Introducing the Model Context Protocol ¥ Anthropic
API・MCP連携に関するFAQ(よくある質問)
- ポートやCORSはどこで設定しますか?
CLI(コマンドライン)を利用する場合、lms server start --port 3000 --corsのようにオプションで指定できます。LM StudioのUI(グラフィカルインターフェース)上でも、サーバー起動設定やネットワーク公開設定が可能です。 - OpenAI SDKはそのまま使えますか?
はい、使用できます。SDKのbase_url(またはbaseURL)を、LM Studioが起動しているローカルアドレス(例: http://localhost:1234/v1)に切り替えるだけで動作します。 - 履歴の送信を減らしたいのですが?
/v1/responsesエンドポイントを使用し、previous_response_idパラメータで前回の応答IDを指定します。これにより、LM Studioサーバー側で会話の状態が管理され、毎回完全な履歴を送信する必要がなくなります。 - ツール呼び出しはどう実装しますか?
/v1/chat/completionsエンドポイントのtoolsパラメータに関数定義を渡します。モデルがツールの実行を要求したら(tool_calls)、アプリケーション側でその関数を実行し、結果をtoolロールのメッセージとしてモデルに再度送信します。ツール呼び出しに対応したモデルテンプレートの使用が安定動作の鍵です。 - MCPの安全対策は?
mcp.jsonには信頼できるサーバーのみを登録することが基本です。強力すぎる権限を要求するMCPは避け、権限を最小限に絞り込みます。また、呼び出しログを定期的に監査し、不審なアクセスがないか監視します。Remote MCP機能は、必要性を吟味した上でオプトイン(明示的に有効化)して使用します。
LM Studioの基本機能とライセンス【商用利用は無料?】
LM Studioは2025年7月から職場利用も無料化され、導入の障壁が下がりました。ここでは運用・API・配布・ライセンスといった実務的な要点に絞って整理します。
本章では、以下の3点について解説します。
- LM Studioで実現できる4つの主要機能
- 商用利用に関する最新のライセンスルール
- 1営業日でPoCを完成させる具体的な4ステップ
それぞれの項目について、詳しく解説します。
LM Studioで実現できる4つのこと
LM Studioの強みは、単なるチャットツールに留まらず、ローカルLLMの「運用装置」としてAPI、実行エンジン、配布機能が揃っている点です。これにより、既存のIT資産(コードや端末)を最大限活かしつつ、実装面の自由度高くAI機能を導入できるため、採用の決め手となります。
実務で特に有効な4つの機能は以下の通りです。
- OpenAI互換API /v1/chat/completions エンドポイントに加え、/v1/responses で会話状態の継続やSSE(Server-Sent Events)配信、推論深度などを細かく制御できます。既存のOpenAI SDKは、接続先URL(base_url)を切り替えるだけで流用できます。
- ツール呼び出しと構造化出力 Function Calling(Tool Use)や、JSONスキーマに準拠した出力に対応しています。これにより、ローカルLLMを社内の業務ロジックや外部APIへ安全に接続できます。
- 実行エンジンの最適化 llama.cpp系(CPU、CUDA、Vulkan、ROCm、Metal)とApple MLXの実行エンジンを選択できます。導入する端末のハードウェア(GPUの有無や種類)に合わせて、推論性能を最大限に引き出せます。
- サーバーとしての自動運用 GUI操作でのローカルサーバー起動やネットワーク公開はもちろん、CLI(コマンドライン)を用いて lms server start --cors のように起動オプションを指定したり、ヘッドレス(GUIなし)で常駐させたり、ログを監視したりといった一貫した運用が可能です。
これらの機能により、既存のコードや端末を活かしつつ、短時間で「動く内製AI」の環境を構築できます。
知っておくべき最新仕様と商用利用のルール
LM Studioは、2025年7月8日以降、職場での利用が明示的に無料と定められました。アプリケーション本体の利用において、個別の商用ライセンス申請は不要です。ただし、SSO(シングルサインオン)連携、モデルやMCP(Model Context Protocol)へのアクセス制御(ゲーティング)、プライベートな設定共有といった組織的な管理機能は、有償のエンタープライズ向けプランで提供されます。 最も重要な留意点は、LM Studio(アプリケーション)の無償化と、実行するLLM(モデル)の利用許諾は別である点です。利用するモデルがApache 2.0やLlama 3のライセンスなど、どのような商用利用条件を定めているかを必ず個別に確認してください。 このライセンス体系により、導入時の稟議(りんぎ)の摩擦を最小化しつつ、モデルのライセンスを確認することで、コンプライアンスを遵守した導入が可能です。
1日でPoC(概念実証)を完成させるための4ステップ
前章で解説したRAGやMCPの基本操作を踏まえ、ここでは1営業日で「再現性のあるPoC(概念実証)」を仕上げる具体的な進め方を紹介します。環境準備、検証、API接続、チーム運用の4ステップで解説します。
ステップ1:環境準備とモデル読込
まず、PoCを行う端末(Windows、macOS、Linux)にLM Studioを導入し、安定動作を確保します。OSやハードウェア(GPUの有無)といった環境差異を吸収し、誰の端末でも再現できる土台を作ることが目的です。 手順として、「Discover」タブから軽量なモデル(例:Llama 3 8B GGUF)を取得し、「Chat」タブで即座に応答するか確認します。Appleシリコン搭載機であればMLXエンジン、NVIDIA製GPU搭載機であればllama.cpp(CUDA)を選択するなど、環境に合わせた高速化設定もこの段階で試行します。 これにより、マシン性能の差を吸収し、誰の端末でも再現できるPoCの土台を作れます。
ステップ2:社内文書での精度検証
次に、実際の社内文書を用いてRAG(文書参照)の精度を検証します。PoCの評価観点(回答の正確性、再現性、根拠の表示)を具体的に確認し、関係者との合意形成を進めるためです。 前章の手順を参考に、機密情報を含まない範囲の社内文書(マニュアルや規定集など)をチャットに添付し、想定されるFAQ(よくある質問)を投げかけてテストを繰り返します。処理はすべてローカルで完結し、文書データは端末外に送信されません。この段階で、評価観点をテンプレート化して記録を残すことが重要です。 守秘義務のある実データで即座に検証できるため、社内規定に沿った形での合意形成が進みます。
ステップ3:API接続と最小改修
検証後は、APIサーバーを起動し、既存のツールやスクリプトとの接続を試みます。これは、接続先URL(base_url)の変更という最小限の改修で、既存システムをローカル推論へ移行できると実証するためです。 「Developer」タブまたはCLI(コマンドライン)でサーバーを起動し、既存コードの接続先を http://localhost:1234/v1 へ切り替えます。Webアプリケーションなどと連携する場合は、--cors オプションでクロスオリジン設定を許可すると開発が円滑に進みます。実際に動作するコード片を成果物として共有することで、技術的な実現可能性を示せます。 URLを差し替えるレベルの最小限の作業で、既存ツール群がローカル推論に移行できることを確認できます。
ステップ4:チーム運用の下地づくり
最後に、構築したPoC環境をチームで共有できる状態に整備します。翌日から複数メンバーが同一の環境を利用し、小規模な横展開(他部署への展開)へスムーズに移行できるようにするためです。 具体的には、サーバーをヘッドレスモード(GUIなし)で常駐起動するように設定し、ログストリーミングで利用状況や応答品質、速度を監視する体制を整えます。必要に応じてネットワーク公開設定(Serve on Network)を有効化し、チーム内の他端末からアクセスできるようにします(職場での利用は無料です)。 これにより、PoCの成果を翌日から小さくチームで共有し、横展開の運用フェーズに素早く入れます。
自社に合うのはどれ?Ollama/Janとの比較と導入ポイント
ローカルLLM基盤は、PoC向きのLM Studio、自動化向きのOllama、ハイブリッド運用のJanで棲み分けられます。機能の見た目だけでなく、自社の運用体制やハードウェア環境に適合する基盤を選ぶことが、導入の失敗を減らす鍵です。
LM Studio・Ollama・Janの特長と違いを比較
ローカルLLM実行ツールは、それぞれ得意分野が異なります。GUI完結のLM Studio、自動化に適したOllama、ハイブリッド運用が可能なJan、それぞれの主要な特長と機能の違いを個別に解説します。
LM Studio:GUI完結のPoC基盤
LM Studioは、ローカルLLMを誰もが容易に扱えるように設計されたGUI完結型アプリケーションです。llama.cppベースのGGUFモデルの取得、対話、RAG(文書添付)、APIサーバー起動までGUIで完結できます。2025年7月から商用利用も無償化されました。WindowsではVulkan経由で Intel / AMD のiGPUにも対応し、専用GPUなしのPCでも実用的な速度が出やすい点が強みです。「手間をかけずに全社PoCを進めたい」場合に最適です。
Ollama:自動化・統合のバックエンド
Ollamaは、自動化やシステム統合に適した開発者向けバックエンドツールです。CLI(コマンドライン)と軽量なサーバー機能が中心で、スクリプト化や組み込みが容易なためです。Windowsネイティブ版も提供されています。iGPU(Intel / AMD 製GPU)の活用はVulkan対応で実験的に進められていますが、現時点では公式サポート外です。自動化やバックエンド統合を前提とする場合に適しています。
Jan:ハイブリッド運用のUIハブ
Janは、ローカル環境とクラウド環境を単一のUIで扱うハイブリッド運用を特徴とします。
ローカルLLMの実行に加え、OpenAI や Anthropic といった外部API(リモートモデル)も同じ画面から切り替えて利用できるためです。直近ではMCP(Model Context Protocol)にも対応し、外部ツールとの連携機能も拡張されています。
「ローカル実行と外部API利用を同居させたい」場合に適したツールとして、普及が進んでいます。
中小企業向けの推奨構成とモデルの選び方
ローカルLLM導入の第一歩は、“手元のPCで無理なく動作する”構成を見つけることです。PCのメモリ(RAM)やVRAM(ビデオメモリ)の容量に合わせてモデルの規模(パラメータ数)を選び、量子化(軽量化)とGPUオフロードを組み合わせて現実的な実行環境を作ります。
ケース1:GPUなし・RAM16GB級のオフィスPC
専用GPUがなくRAM 16GBのPCでは、3B〜7Bクラスのモデルを検証用途で動作させられます。CPUのみでの実行はメモリ上可能ですが、推論速度が遅くなる傾向があり、実用には時間がかかる場合があります。
たとえば、Mistral 7BやGemma 3系モデルを量子化して社内FAQや要約を試すことはできますが、応答速度はGPU環境に比べ遅くなります。
まずはLM StudioのRAG機能で精度を検証し、実運用では軽量モデルやGPU環境を検討するのが現実的です。
ケース2:ミドルGPU(VRAM 8~12GB)・RAM32GB級
VRAM(ビデオメモリ)が8GBから12GB程度のミドルクラスGPUを搭載し、RAM 32GB級のPCでは、13Bから20Bクラスのモデルが現実的な選択肢となります。Qwen3-14BやGemma 3 12Bの量子化版、あるいはOpenAIが公開したgpt-oss-20Bなどが選択肢に入ります。快適な動作を目指すには、モデル全体をVRAMに収め、全レイヤー(処理層)をGPUで処理することが理想です。モデルをVRAMに収め切ることが、CPU実行時とは比較にならない体感速度を実現する鍵です。
ケース3:ノート/ミニPC(Intel/AMDのiGPU活用)
専用GPU(dGPU)がないノートPCやミニPCでも、iGPU(内蔵GPU)を活用する道があります。特にLM StudioはVulkan(グラフィックスAPI)に対応しており、これを利用してiGPUに処理をオフロードすることで、CPU単独での実行時よりも実用的な速度が期待できます。7Bクラスのモデルを量子化するとともに、OS設定でGPU共有メモリ(メインメモリの一部を使用)を増やすといった対策が効果的です。iGPUであっても、ツールと設定次第で“使える速さ”を実現できる場面が増えています。
コストとライセンス
ローカルLLMの導入コストは、既存のPC端末を再利用する場合、低額あるいはゼロに抑えられます。導入時に法務上、最も重要なのは、実行ツール(アプリ)と利用するLLMモデル、双方のライセンス(利用許諾)です。主な運用コストは推論処理にかかる電気代や、将来的な機材更改費用といった社内コストが中心となります。 LM Studio本体は2025年7月にポリシーが変更され、商用利用も無償になりました。しかし、OllamaやJan(OSS)を含め、LM Studioで実行するモデル自体のライセンスは様々です。例として、Qwen3はApache 2.0、Gemma 3は利用制限のある独自ライセンス、OpenAIのgpt-oss-20BなどはApache 2.0で提供されています。商用利用の可否、生成物の配布条件、モデル自体の再頒布可否などを「モデルごと」に確認する必要があります。「アプリのライセンスがOKでも、モデルのライセンスがNG」という事態もあり得るため、利用条項の確認は必須です。
まとめ
LM Studioは、社内でローカルLLMを安全かつ迅速に試すための有力な選択肢です。GUIでRAG、OpenAI互換API、MCPを備え、Vulkan経由のiGPU活用と商用無料により導入障壁が低い点が特長です。処理データは端末内にとどまるため、プライバシー面でも安全です。PDF添付の社内QAやツール連携の自動化、軽量モデルの実行がノートPCでも即日試行できます。PoCはLM Studio、システム統合はOllama、ハイブリッド運用はJanという使い分けを参考に、まずはLM Studioで安全なPoCを始めてみましょう。
HPは、ビジネスに Windows 11 Pro をお勧めします。
Windows 11 は、AIを活用するための理想的なプラットフォームを提供し、作業の迅速化や創造性の向上をサポートします。ユーザーは、 Windows 11 のCopilotや様々な機能を活用することで、アプリケーションやドキュメントを横断してワークフローを効率化し、生産性を高めることができます。
組織において Windows 11 を導入することで、セキュリティが強化され、生産性とコラボレーションが向上し、より直感的でパーソナライズされた体験が可能になります。セキュリティインシデントの削減、ワークフローとコラボレーションの加速、セキュリティチームとITチームの生産性向上などが期待できる Windows 11 へのアップグレードは、長期的に経済的な選択です。旧 Windows OSをご利用の場合は、AIの力を活用しビジネスをさらに前進させるために、Windows 11 の導入をご検討ください。
※このコンテンツには日本HPの公式見解を示さないものが一部含まれます。また、日本HPのサポート範囲に含まれない内容や、日本HPが推奨する使い方ではないケースが含まれている可能性があります。また、コンテンツ中の固有名詞は、一般に各社の商標または登録商標ですが、必ずしも「™」や「®」といった商標表示が付記されていません。

ハイブリッドワークに最適化された、Windows 11 Pro+HP ビジネスPC
ハイブリッドなワークプレイス向けに設計された Windows 11 Pro は、さらに効率的、シームレス、安全に働くために必要なビジネス機能と管理機能があります。HPのビジネスPCに搭載しているHP独自機能は Windows 11 で強化された機能を補完し、利便性と生産性を高めます。
詳細はこちら




