【検証事例・株式会社NTTデータMSE】ローカルLLMを利用して非構造データを構造化しデータ活用を促進
2025-07-08

今回のPoCは株式会社NTTデータMSEにて行われたもので、同社の担当者である中島 憲一郎氏と田中 篤史氏、ワークステーションの提供元となる株式会社 日本HPの大津山氏、AI活用アドバイザーに株式会社Workstyle Evolutionの池田 朋弘氏、システム開発として株式会社WEELの田村 洋樹氏と萩原 佳太氏を迎えて、中間報告会を開催した。NTTデータMSEの中での生成AIのローカル活用はどのように進んだのか、レポートしたいと思う。
取材:中山 一弘

AI活用を推進するための可能性を模索
2023年から生成AI活用の可能性を模索していたNTTデータMSE。「HP様からPoCのお話しをいただいた当時、社内でいくつも走っているスライド資料などのプロジェクト情報の利活用がうまくできておらず課題となっていました。そのため、AIをつかってうまく整理しようと思いましたが、こうした資料には表や画像、文章など様々な情報が入り交ざっているため、そのまま読み取らせてもスライドのページ構成が破綻することがあり、うまく再利用できませんでした。それらの情報の中には次のプロジェクトに活かせるものも多いので、諸問題を解決してAIで必要な情報を正確に見つけたり、取り出したりできるようにしたいと考え、それをテーマとすることにしました」と中島氏は今回のPoCを実施した理由を語る。

NTTデータMSEの課題を受け、池田氏は今回のPoCに必要なシステムへの構想を練る。「社内の重要データ活用ということもあり、ローカルLLMを使えばセキュアに処理ができますし、まずはそれを前提でアイデアを練りました。例えばプロジェクト管理というひとつの目的のためだけに独自ツール開発を進めると汎用性がなくなるので、『Dify』を活用することにしました。NTTデータMSE様では、Difyをすでにご利用中だったので、社内での再利用も容易と考えました」と同氏は語る。
「Difyもよいのですがすべての処理をさせると追いつかない部分もあるので、構造化処理に『FastAPI』を使った部分もあります。ここへ非構造データを入れると構造化データに書き換えられるという仕組みです」と開発を担当した田村氏は語る。
「最終的にローカルLLMのモデルには『gemma3:27b』を、埋め込みモデルには『bge-m3』を用いました。日本語に対する精度が高いことや、非構造化データを構造化する能力に優れていたためです。それら各種モデルをDifyへ繋ぎ込み、検証しやすい形にしています」と同じく開発担当の萩原氏は解説する。
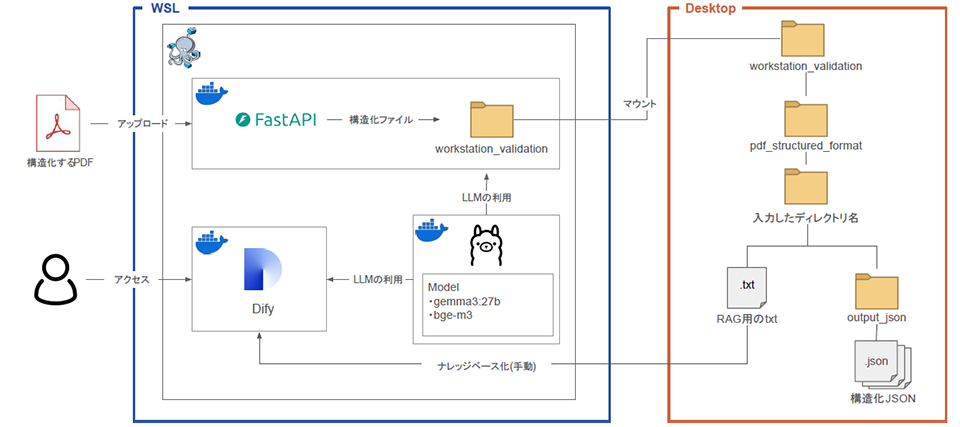
このような各モデルやツールを使った、NTTデータMSEで課題となる非構造データを構造化しローカル環境で生成AI活用ができるようにするというPoCがスタートすることとなった。

ローカルLLMを身近に運用
これらを稼働させるプラットフォームとして、今回選ばれたのはHPワークステーションの「HP Z6 G5 A Workstation」だ。「社外へ出るといけない情報であるため、当初からオンプレミス環境での生成AIシステムを構築するというお話しをいただいていました。さらに拡張性も考慮し、今回のPoCに最適なプラットフォームとして弊社のワークステーションの中から、こちらの製品をご提供させていただきました」と語るのはHPの大津山氏だ。

今回のPoCのために用意されたHP Z6 G5 A Workstationは、プロセッサには物理コア数16、最大5.3GHzで動作する AMD Ryzen™ Threadripper™ PRO 7955WX 、GPUには NVIDIA® RTX 5000 Ada 32GB がそれぞれ採用されている。さらにメインメモリは64GB、ストレージは2TBのHP Z Turboドライブを搭載している。
HP Z6 G5 A Workstationでは AMD Ryzen™ Threadripper™ PRO プロセッサの最上位モデルは物理コア96の7995WXまで選択でき、グラフィックスも NVIDIA® のGPUカードを最大3基まで搭載することが可能だ。今回のスペックは標準的な内容であり、スケールアップを視野に入れた場合のデータ収集にも最適な内容となっている。

「このワークステーション上で今回のシステムを動作させた場合、画像認識の部分で1スライドにつき1~5分程度の時間が掛かりました。特に複雑な構成のスライドほど何段階ものLLMによる処理を動かしているので、もっと長い時間が必要かと予想していましたが、実際には比較的ストレスなく処理できていると思います」と萩原氏は語る。
「LLMに関しても27B(ビリオン)のマルチモーダルモデルですが、十分動作するという感覚です。ですから、今回のPoC用として用意していただいたHP Z6 G5 A WorkstationはNTTデータMSE様の課題解決に最適な仕様といえます」と田村氏。HPが用意したHP Z6 G5 A Workstationは、今回のPoCに際してストレスのない環境を提供したようだ。
非構造データを構造化データへ
PoC用のシステム環境の構築はわずか1週間程度と短期間で済み、いよいよ実証実験へとステージは移行する。「例えば、表があったとして、セルを結合した部分や、空欄があるといっただけで読み取りづらいものがありました。それに対応する処理を挟むと精度もよくなるので、当初は地道な作業が多かったですね」と田村氏は振り返る。
ほかにも組織図のような複雑な図やマルチカラムを含むスライドの読み取りが苦手であるといったように、精度が悪いあるいはムラが出るものもあり、都度読み取りやすくする工程を挟んでいくことで、最終的にテキストやJSONデータへと変換。構造化されたデータを受け取るDifyやLLMが利用しやすい形態にしていくことで、これまで再利用が難しかった非構造データが再利用可能な情報になることが確認できたのだという。
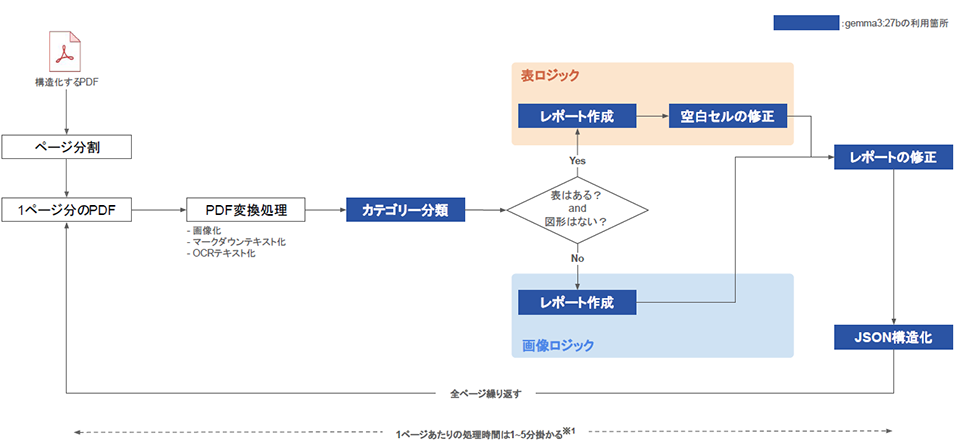
「いままでは雑多にあるだけの提案データがきちんと分類され、十分な手応えを感じることができるレベルといえます。PoCはまだ途中ですが、ここまでの成果は期待していた通りと捉えています」と田中氏は現時点での感想を語る。
「構造化する際に、最初からすべてを正確にデータ化しようとするのではなく、段階的に処理していくのが重要です。今回のプロジェクト資料では、まず1スライドずつ、どんなパターンのスライドなのかを個別に分類し、その後に各スライドをテキスト化します。現在のAIでは、テキスト化の精度は100%には到底ならず、数値や内容のミスも起こりますが、スライド別に分類されていれば、多少内容が間違っていても、後から検索・利用しやすいわけです」と池田氏も現時点での結果に満足している。
PoCは社会実装を目指す次のステップへ
「そもそもAMDプロセッサを搭載したワークステーション1台でここまでの生成AIシステムが構築できることを確認できたのが、もっとも大きな収穫といえます。これまではクラウドサービスを提案することが多く、ローカルサービスというものがそもそもなかったので、生成AIのローカル活用という点で社内外問わずにご提案できる幅が広がりました」と田中氏もここまでの感想を語る。
「今回の仕組みは画像認識が多いこともあってGPUへの依存率が高かったですが、API処理の部分をマルチスレッドに対応させることで、更なる効率化が実現できそうだと考えています。一度に処理をするスライドが20、30とあった場合、マルチプロセスで処理できれば、相当な時間的圧縮ができます。そういう意味ではまだまだチャレンジするところがありそうです」と萩原氏も次のステップにかける思いを語る。
「今回のPoCにご活用いただいているHP Z6 G5 A Workstationは、オフィスに設置されていると伺いました。オンプレミスでの生成AI活用というと大規模なGPUサーバを連想しがちですが、PoCの際にはワークステーションでも十分実施可能なことを証明していただけました。100V電源で十分動作しますし、私たちのワークステーションはエアフロ―の最適化と専用の内部レイアウトによって冷却効率と静音性が非常に高く、手元に置いても邪魔になりません。さらに、拡張性を考えると、ここから部門単位での実運用にも応えることが可能です。身近にはじめるローカル生成AI活用には最適な環境をご提供できると思います」と、大津山氏もPoCの良好な経過に満足した表情を見せる。
「いま私たちで作り上げようとしているAIシステムは社外向けのサービスへの転用も考えてのものです。私たちのお客様には製造業者様も多くいらっしゃるのでクラウドには抵抗がある企業様も多いのが実情です。そのようなお客様が実際に社内に持っている膨大な非構造データもこのように再利用できる可能性が高いことが分かれば、製造業者様の生成AI活用が促進されるかもしれません。それにはローカル環境で構築できる今回のPoCのシステムは非常に参考になりますし、とてもよいノウハウを得られていると思います」と中島氏は今後の展望を語ってくれた。
NTTデータMSEのPoCは今後、蓄積した構造化データをRAGで高精度な情報検索と該当資料の参照の実現、およびJSONデータを編集した際に対応スライドにもそれを反映させる機能の実装という目標へと進んでいく。HPは今後もNTTデータMSE、Workstyle Evolution、WEELらが中心となって進めているPoCのサポートを続ける。

※このコンテンツには日本HPの公式見解を示さないものが一部含まれます。また、日本HPのサポート範囲に含まれない内容や、日本HPが推奨する使い方ではないケースが含まれている可能性があります。また、コンテンツ中の固有名詞は、一般に各社の商標または登録商標ですが、必ずしも「™」や「®」といった商標表示が付記されていません。





